PatchRNN

PatchRNN is a deep learning based model to identify security patches in software using recurrent neural networks.
PatchRNN is a deep learning based model to identify security patches in software using recurrent neural networks. Due to the different structures of patch components, PatchRNN tends to process the commit message and the code revision individually hence conducting a more comprehensive analysis. The code revision in patches is processed using a twin RNN model with a static analytic tool, while the commit message is processed with a TextRNN model with NLP techniques. Afterward, the information from the commit message and the code revision is fused to get the final prediction using a multi-layer perceptron.
More details about the PatchRNN can be found in the paper “PatchRNN: A Deep Learning-Based System for Security Patch Identification”, to appear in the IEEE/AFCEA MILCOM 2021, San Diego, USA, November 29–December 2, 2021.
If you are using PatchRNN for work that will result in a publication (thesis, dissertation, paper, article), please use the following citation:
@INPROCEEDINGS{PatchRNN2021Wang,
author={Wang, Xinda and Wang, Shu and Feng, Pengbin and Sun, Kun and Jajodia, Sushil and Benchaaboun, Sanae and Geck, Frank},
booktitle={MILCOM 2021 - 2021 IEEE Military Communications Conference (MILCOM)},
title={PatchRNN: A Deep Learning-Based System for Security Patch Identification},
year={2021},
pages={595-600},
doi={10.1109/MILCOM52596.2021.9652940}
}
To download the PatchRNN demo program, please use this link. This demo program is based on the PatchRNN Developer Edition (S2020.08.08-V4), developed by Shu Wang. You can follow the provided instructions to run this demo.
PatchRNN design
1. Overview
Figure 1 presents the architecture of our PatchRNN toolkit. Since a commit (i.e., a patch file) is composed of code revision and commit message, we utilize both parts to capture more comprehensive features. For code revision, we reconstruct the unpatched code and patched code and process them separately with the same tokenization and abstraction strategies. Then a twin RNN model is adopted to generate the code vector representation. For the commit message, we utilize the NLP toolkit to process the text sequences and employ a TextRNN model to obtain vector representation for commit message. The final results are derived from the feature vectors of both parts. We use a large-scale patch dataset PatchDB to train the model. The size of the dataset is 38K.
Figure 1: The architecture of PatchRNN model.
From the perspective of process flow, our system can be divided into 4 phases: text processing, featurization, RNN-based feature vector extraction, and finial identification. From the perspective of process objects, our system can be divided into 3 modules: code revision processing, commit message processing, and fused predictive modeling.
2. Code revision processing
- code revision extraction:
ReadDiffLines(filename)inReadData() - tokenization:
GetDiffProps(data)- code tokenization:
tk - token type recognition:
tkT - diff type recognition:
dfT
- code tokenization:
- token preprocessing:
ProcessTokens(props, dType=1, cType=1)- maintain context?
dType - maintain comments?
cType
- maintain context?
- token abstraction:
AbstractTokens(props, iType=1, lType=1)- how to abstract identifiers?
iType - how to abstract literals?
lType
- how to abstract identifiers?
- token embedding generation:
GetDiffEmbed(tokenDict, embedSize) - unpatched and patched code division:
DivideBeforeAfter(diffProps) - unpatched and patched code preprocessing
- indexed data convertion:
GetTwinMapping(props, maxLen, tokenDict) - one-hot data convertion:
UpdateTwinTokenTypes(data)
- indexed data convertion:
- twin RNN model
# twin 1. xTwin = x[:, :_TwinMaxLen_, :6] embedsTwin = self.embedTwin(xTwin[:, :, 0]) features = xTwin[:, :, 1:] inputsTwin = torch.cat((embedsTwin.float(), features.float()), 2) inputsTwin = inputsTwin.permute(1, 0, 2) lstm_out, (h_n, c_n) = self.lstmTwin(inputsTwin) featMapTwin1 = torch.cat([h_n[i, :, :] for i in range(h_n.shape[0])], dim=1) # twin 2. xTwin = x[:, :_TwinMaxLen_, 6:-1] embedsTwin = self.embedTwin(xTwin[:, :, 0]) features = xTwin[:, :, 1:] inputsTwin = torch.cat((embedsTwin.float(), features.float()), 2) inputsTwin = inputsTwin.permute(1, 0, 2) lstm_out, (h_n, c_n) = self.lstmTwin(inputsTwin) featMapTwin2 = torch.cat([h_n[i, :, :] for i in range(h_n.shape[0])], dim=1) # combine twins. featMap = torch.cat((featMapTwin1, featMapTwin2), dim=1)
3. Commit message processing
- commit message extraction:
ReadCommitMsg(filename)inReadData() - commit message preprocessing:
GetCommitMsgs(data)- URL removel
- independent number removel
- lower case convertion
- footnote removel
- word tokenization
- non-english letter verification
- stopword clearance
- word stemming
- word embedding generation:
GetMsgEmbed(tokenDict, embedSize) - embedding mapping:
GetMsgMapping(msgs, maxLen, tokenDict) - TextRNN model
# msg. xMsg = x[:, :_MsgMaxLen_, -1] embedsMsg = self.embedMsg(xMsg) inputsMsg = embedsMsg.permute(1, 0, 2) lstm_out, (h_n, c_n) = self.lstmMsg(inputsMsg) featMapMsg = torch.cat([h_n[i, :, :] for i in range(h_n.shape[0])], dim=1)
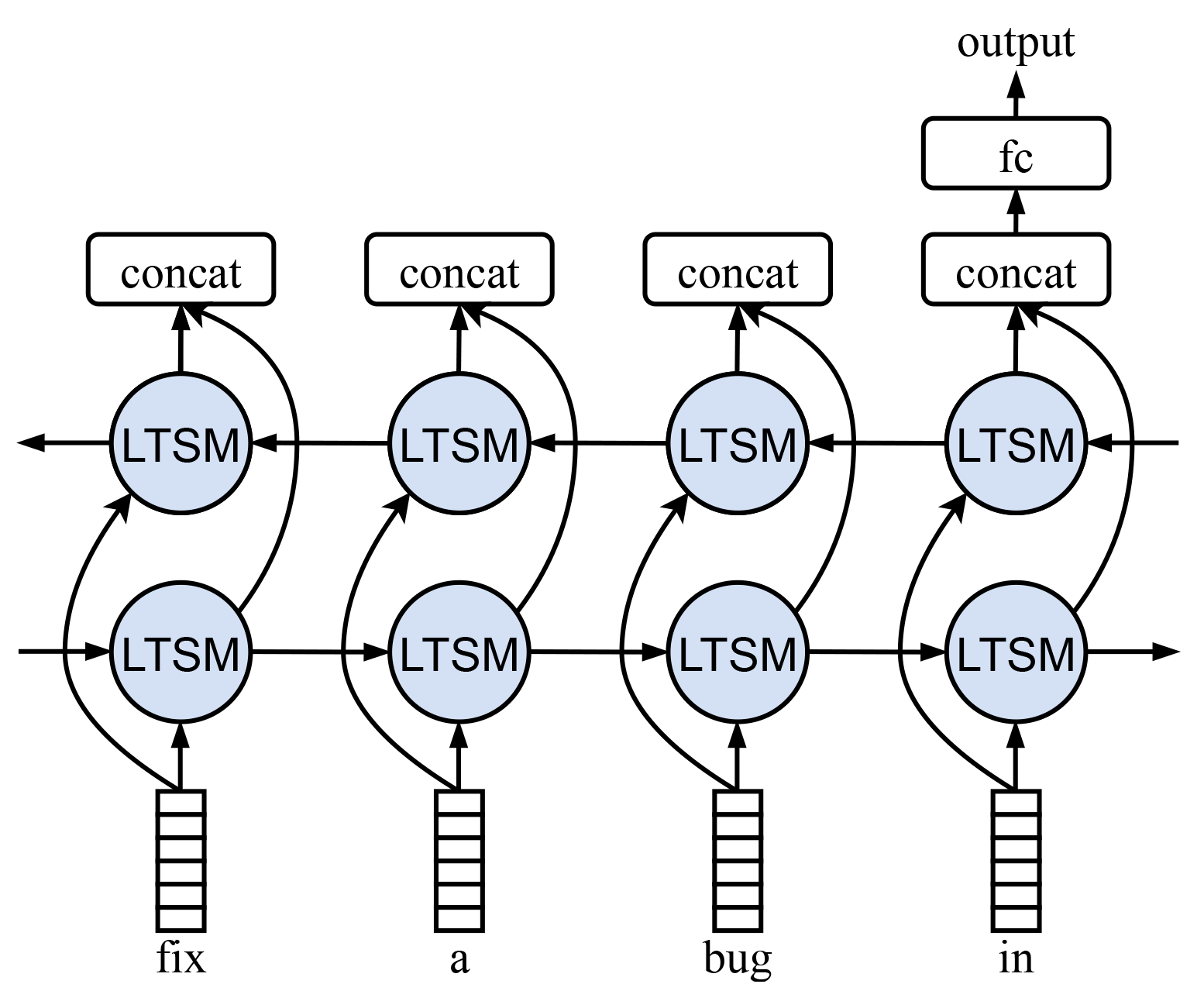
Figure 2: The structure of TextRNN model.
4. Fused predictive modeling
- fully-connected network
# fc layers. featMap = self.fc1(featMap) if (0 == _TWIN_): # (only twins). final_out = self.fc2(featMap) elif (1 == _TWIN_): # (twins + msg). featMap = torch.cat((featMap, featMapMsg), dim=1) featMap = self.fc3(featMap) final_out = self.fc4(featMap) return self.softmax(final_out)
How to run PatchRNN-demo
1. Install OS
We use Ubuntu 20.04.3 LTS (Focal Fossa) desktop version.
Download Link: https://releases.ubuntu.com/20.04/.
The virtualization software in our experiments is VirtualBox 5.2.24.
Download Link: https://www.virtualbox.org/wiki/Download_Old_Builds_5_2.
You can use other software like VMware Workstation.
System recommendation configurations:
RAM: >=2GB
Disk: >=25GB
CPU: 1 core in i7-7700HQ @ 2.8GHz
2. Download the source code from github
We use home directory to store the project folder.
cd ~
Install git tool.
sudo apt install git
Download PatchRNN-demo project to local disk. (You may need to enter your github account/password.)
git clone https://github.com/shuwang127/PatchRNN-demo
3. Install the dependencies.
3.1 Install pip tool for python3.
sudo apt install python3-pip
3.2 Install common dependencies.
pip3 install nltk==3.3
pip3 install natsort
pip3 install pandas
pip3 install sklearn
3.3 Install CPU-version PyTorch. Official website: https://pytorch.org/.
pip3 install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
3.4 Install clang tool.
pip3 install clang==6.0.0.2
Configurate the clang environment.
sudo apt install clang
cd /usr/lib/x86_64-linux-gnu/
sudo ln -s libclang-*.so.1 libclang.so
4. Run the demo program.
cd ~/PatchRNN-demo/
python3 demo.py
There are 56 input test samples stored in ~/PatchRNN-demo/testdata/, the logging file of running demo is stored in ~/PatchRNN-demo/logs/PatchRNNdemo.log.
cat logs/PatchRNNdemo.log
We can find the logging results.
[INFO] <ReadData> Save 56 raw data to .//tmp//testdata.npy. [TIME: 0.05 sec]
[INFO] <GetDiffProps> Processing Tokens 1/56... [TIME: 3.16 sec]
...
[INFO] <GetDiffProps> Processing Tokens 56/56... [TIME: 63.98 sec]
[INFO] <GetDiffProps> Save 56 diff property data to .//tmp//testprops.npy. [TIME: 63.99 sec]
[INFO] <ProcessTokens> Delete the comment parts of the diff code. [TIME: 64.01 sec]
[INFO] <AbstractTokens> Abstract the tokens of identifiers with iType 1 (VARn/FUNCn). [TIME: 64.04 sec]
[INFO] <AbstractTokens> Abstract the tokens of literals, and comments with iType 1 (LITERAL/n/COMMENT). [TIME: 64.04 sec]
[INFO] <GetDiffEmbed> Create pre-trained embedding weights with 35575 * 128 matrix. [TIME: 64.37 sec]
[INFO] <DivideBeforeAfter> Divide diff code into BEFORE-version and AFTER-version code. [TIME: 64.38 sec]
[INFO] <DivideBeforeAfter> The max length in BEFORE/AFTER-version code is 2994 tokens. (hyperparameter: _TwinMaxLen_ = 800) [TIME: 64.38 sec]
[INFO] <GetTwinMapping> Create 56 feature data with 800 * 4 matrix. [TIME: 64.42 sec]
[INFO] <GetTwinMapping> Create 56 labels with 1 * 1 matrix. [TIME: 64.42 sec]
[INFO] <UpdateTwinTokenTypes> Update 56 feature data with 800 * 12 matrix. [TIME: 64.45 sec]
[INFO] <GetCommitMsg> Processing Commit 1/56... [TIME: 64.49 sec]
...
[INFO] <GetCommitMsg> Processing Commit 56/56... [TIME: 65.93 sec]
[INFO] <GetCommitMsg> Save 56 commit messages to .//tmp//testmsgs.npy. [TIME: 65.93 sec]
[INFO] <GetMsgEmbed> Create pre-trained embedding weights with 80831 * 128 matrix. [TIME: 66.69 sec]
[INFO] <GetMsgMapping> Create 56 feature data with 1 * 200 vector. [TIME: 66.7 sec]
[INFO] <GetMsgMapping> Create 56 labels with 1 * 1 matrix. [TIME: 66.7 sec]
[INFO] <CombineTwinMsgs> Combine the twin props with the commit messages. [TIME: 66.7 sec]
[INFO] <demoTwin> Load model parameters with GPU-torch! [TIME: 69.14 sec]
[INFO] <TwinRNNTest> Finish the prediction of test data. [TIME: 70.48 sec]
[INFO] <SaveResults> Save the final results in .//results/results.txt [TIME: 70.48 sec]
The output results are saved in ~/PatchRNN-demo/results/results.txt.
cat results/results.txt
You can find the results as the format of filepath and prediction.
.//testdata/nginx/release-1.19.0_release-1.19.1/0a683fdd.patch,1
.//testdata/nginx/release-1.19.0_release-1.19.1/1bbc37d3.patch,1
.//testdata/nginx/release-1.19.0_release-1.19.1/2afc050b.patch,0
.//testdata/nginx/release-1.19.0_release-1.19.1/2d4f04bb.patch,0
.//testdata/nginx/release-1.19.0_release-1.19.1/6bb43361.patch,1
...
1s means security patches, and 0s means non-security patches.
